

Resumen ejecutivo
- El monitoreo de opinión pública mediante NLP permite modelar tendencias con un margen de error menor al 3%.
- La depuración de ruido (trolls y bots) elimina más del 90% de interacciones irrelevantes.
- El análisis semántico supera al análisis sintáctico al interpretar el contexto y el doble sentido en español.
Nota del Editor: Este artículo analiza cómo el monitoreo de medios digitales y el procesamiento de lenguaje natural (NLP) permiten realizar modelos predictivos eficientes en procesos electorales y de opinión pública.
El uso de metodologías de escucha activa en canales digitales representa un cambio de paradigma en la toma de decisiones estratégicas. En lugar de limitarse a auditorías de datos históricos, la integración de social media listening con IA facilita la detección temprana de tendencias, opiniones clave y posicionamientos reputacionales.
Monitoreo digital para predicción de tendencias: de la idea al resultado
El objetivo inicial consistió en desarrollar un modelo capaz de registrar la percepción sobre la gestión y la imagen digital de diversos candidatos políticos, proyectando su intención de voto con un margen de error mínimo en un escenario altamente cambiante.
Retrospectiva del análisis de opinión digital
En los inicios de SciData Argentina, el desafío principal radicaba en ofrecer una propuesta diferente a los tradicionales reportes estáticos. En lugar de proveer resúmenes del pasado, la meta fue consolidar un sistema predictivo capaz de anticipar escenarios antes de que ocurran los eventos electorales.
El listening de medios consiste en la estructuración de búsquedas avanzadas que tienen como entrada palabras clave, entidades y combinaciones conceptuales procesadas desde diversos canales digitales en internet: foros, portales de noticias, blogs y redes sociales públicas.

Procesamiento y correlación semántica de datos
El éxito de una estrategia de escucha activa radica en la capacidad de procesar las coincidencias textuales de manera estructurada e inteligente. Una vez recopiladas las menciones públicas, las tecnologías de inteligencia artificial se encargan de catalogar, limpiar y clasificar la información bajo criterios semánticos unificados.
Clasificación y análisis de sentimiento NLP
La descarga y almacenamiento de las menciones es solo el primer paso. Posteriormente, los motores de Procesamiento del Lenguaje Natural (NLP) categorizan la información en subgrupos temáticos (por ejemplo, preocupaciones económicas, percepción de imagen o propuestas específicas) y determinan la valoración o sentimiento expresado (positivo, negativo o neutral).
En esta etapa de interpretación, la intervención de expertos lingüistas es fundamental para calibrar el algoritmo, permitiendo identificar correctamente dobles sentidos, ironías y ambigüedades idiomáticas que los motores puramente automáticos suelen malinterpretar.
Tratamiento de perfiles inauténticos (Trolls y Bots)

Respecto al tratamiento de perfiles automatizados o “trolls”, la exclusión es severa y automática. Mediante filtros avanzados de influencia, volumen de publicación diaria y relación de seguidores/seguidos, se descarta más del 90% del ruido inauténtico, asegurando que las tendencias finales reflejen interacciones de usuarios reales.
El experimento de predicción electoral en Argentina 2019
El modelo predictivo de SciData se puso a prueba analizando el comportamiento de las elecciones presidenciales de 2019. El algoritmo procesó menciones digitales traduciéndolas a un indicador de respaldo político neto.
A diferencia de las metodologías de encuestas tradicionales por muestreo telefónico, la medición volumétrica y de sentimiento digital permitió proyectar la diferencia electoral de las elecciones primarias (PASO) con una precisión cercana al 90%.
Análisis Comparativo de Metodologías
Para entender el valor de este enfoque, resulta útil contrastar la metodología tradicional con la inteligencia social predictiva implementada por SciData:
| Característica | Monitoreo Tradicional (Clipping) | Inteligencia Social Predictiva (SciData) |
|---|---|---|
| Enfoque de Análisis | Reactivo (análisis post-mortem) | Proactivo (predicción de tendencias futuras) |
| Volumen de Datos | Muestras limitadas o manuales | Procesamiento masivo de datos públicos |
| Tratamiento del Ruido | Inclusión involuntaria de bots y trolls | Filtrado automático superior al 90% de cuentas falsas |
| Comprensión del Sentimiento | Reglas sintácticas rígidas | Modelos semánticos avanzados con lingüística de apoyo |
| Resultados | Reportes estáticos descriptivos | Modelos de probabilidad y tendencias electorales |
Resultados y proyecciones del modelo
El sistema no solo anticipó el escenario de primera vuelta en Argentina, sino que también identificó la recuperación de la fórmula oficialista hacia el final de la campaña, proyectando una brecha de alrededor de 9 puntos porcentuales que la mayoría de los análisis convencionales omitían.
Al consolidar los resultados finales de respaldo digital, el binomio de la oposición alcanzó un 46,49% de menciones favorables netas frente al 39,48% del oficialismo, estrechamente alineado con el resultado oficial de la elección general.
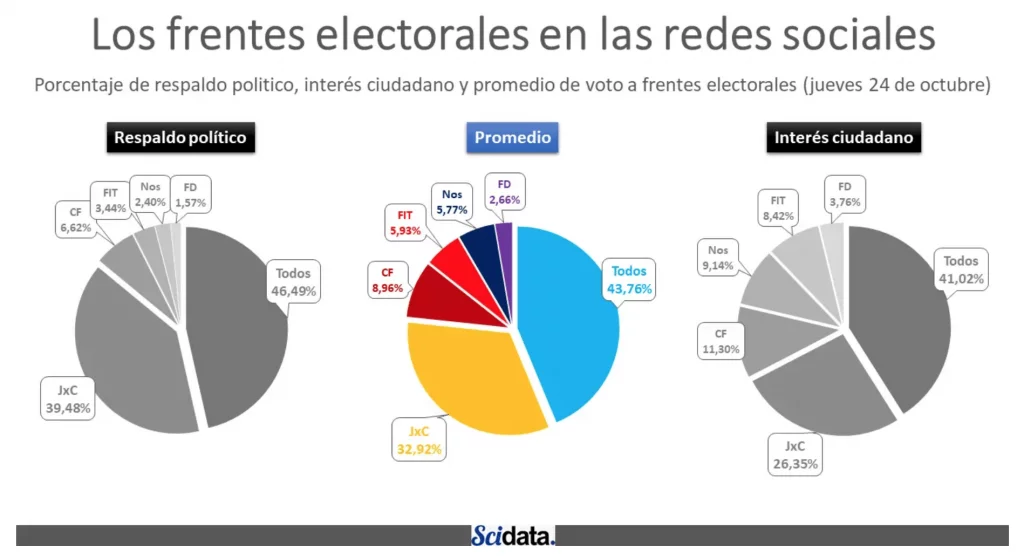
El algoritmo de “Respaldo político” a la izquierda, utilizado como modelo de proyección para las elecciones generales de 2019.
Futuro y perspectiva del monitoreo social predictivo
El desarrollo y optimización de estas metodologías predictivas requiere una inversión constante en investigación y desarrollo. La meta de SciData consiste en incrementar la precisión predictiva actual —que ronda el 93%— hasta alcanzar un estándar del 97% al 98% en los próximos modelos de simulación de opinión pública.
Autores del Proyecto: Diego Corbalán y Gustavo Papasergio
Para conocer cómo aplicar el análisis predictivo y el social listening en la toma de decisiones estratégicas de su empresa, le invitamos a ponerse en contacto con nuestro equipo.
Sobre este artículo
| Campo | Detalle |
|---|---|
| Publicado | 1 de octubre de 2024 |
| Autor | Gustavo Papasergio |
| Temas | Social Listening, Inteligencia Artificial, Modelado Predictivo |
Preguntas Frecuentes
- ¿Cómo se puede predecir el resultado de elecciones con monitoreo digital?
- Analizando el volumen y sentimiento de menciones en redes y medios digitales en tiempo real. El cambio brusco en el ratio de menciones positivas/negativas hacia un candidato suele anticipar movimientos en intención de voto que las encuestas tradicionales tardan días en capturar.
- ¿Qué papel juega Social Listening en análisis electorales?
- Permite medir en tiempo real la evolución del sentimiento hacia candidatos y partidos, detectar narrativas emergentes y estimar intención de voto a partir de señales conversacionales. Es especialmente útil en contextos de alta volatilidad electoral donde las encuestas tienen márgenes de error elevados.
